Введение
НЯРС (Новый Японско-Русский Словарь) - открытый редактируемый японско-русский словарь.
НЯРС создавался как словарь для практической работы с японским языком, преимущественно современным.
Зачем
Основная фича НЯРСа — это редактируемость и свободная расширяемость.
Подобные словари существуют для китайского (大БКРС), английского (мультитран), но в случае японского такие проекты если и были, то они были заморожены.
Кроме того, НЯРС технически постоянно развивается, а пользователи могут принимать активное участие в обсуждении нового функционала.
С чего начать
Ввести интересующее слово в строку поиска и нажать Enter =)
Если интересуют продвинутые возможности, посмотрите «Как пользоваться поиском», «Как создать/отредактировать первую статью»
Как связаться
По всем вопросам пишите в наше сообщество в Discord'е: https://discord.gg/u7H5nsPWVB
И напоследок
Если вы нашли неточности/ошибки в руководстве или, может, что-то описано слишком заумным языком, вы можете исправить это в репозитории руководства, либо написать нам в Discord.
Поиск
Поиск производится как по заголовку статьи, так и по её содержанию.
Ниже приведены примеры поисковых запросов:
- Поиск по японскому: 沸かす, わかす
- Поиск по форме слова: 沸かした
- Поиск по транскрипции: zyunban, вакасита
- Разбор предложения по словам: お湯を少し沸かしてください。
- Поиск по русскому/английскому языку: кипятить, boil
- Поиск по тегам: #jlpt-n4, #comp сбой
Словари
Несмотря на название, НЯРС включает в себя несколько разных словарей:
- Японско-русский словарь
Русско-японский словарьСловарь иероглифов- Словарь имён
- Словарь примеров
* перечёркнутые на данный момент ещё не реализованы
Особенности структуры и редактирования каждого из них разобраны далее в этом руководстве.
Словарь имён предназначен для обезличенных имён собственных. 暁なつめ -- Нацумэ Акацуки, это конкретная личность, поэтому имя нужно включать в японско-русский словарь, однако 暁 и なつめ можно по отдельности включить в словарь имён с пометками «имя»/«фамилия». 沢山 -- как конкретная деревня может быть включена в японско-русский словарь (такая-то деревня в таком-то регионе), но также может быть включена и в словарь имён (просто как топоним, без конкретики).
В словарь примеров включаются полноценные предложения. По своей сути этот словарь является упрощённым корпусом, по которому можно посмотреть употребление слов в контексте. Как правило, примеры отличает от слов наличие грамматической структуры, однако обратите внимание, что различные устойчивые выражения необходимо также включать в японско-русский словарь, а не в словарь примеров.
Рейтинг
За работу над словарём пользователям начисляется рейтинг в зависимости от их вклада. Соотношение следующее:
- Японско-русский словарь: +2 за исправление, +3 за новую статью
- Русско-японский словарь: +2 за исправление, +3 за новую статью
- Словарь иероглифов: +3 за исправление, +3 за новую статью
- Авто-исправления: +1 балл
- Проверка чужих правок: +1 балл
Загрузки
На данном этапе развития словаря возможность скачивать предоставляется только пользователям, внёсшим небольшой вклад в развитие словаря (15 недельного рейтинга, см. «Рейтинг»).
При этом для скачивания доступна только та часть базы, которая редактировалась сообществом (в НЯРСе есть начальный набор статей, сформированный из различных списков слов, открытых словарей и т.п. По умолчанию такие статьи считаются «Неотредактированными»).
Доступные форматы
- Plain Text (обычный текстовый файл)
- Yomichan
Список доступных форматов будет пополняться по мере необходимости.
Настройки
Страница настроек пока в разработке, но скоро тут точно что-то будет
(ノ>ω<)ノ :。・:*:・゚’★,。・:*:・゚’☆
Правки
Редактирование в НЯРСе реализовано при помощи системы правок. Благодаря ей пользователи могут предлагать изменения, а модераторы проверять их.
Список последних правок на данный момент выводится на главной странице, при этом непроверенные выводятся выше остальных.
Типы правок различаются в зависимости от словаря:
- яп-ру - Японско-русская статья
- ру-яп - Русско-японская статья
- кандзи - Словарь иероглифов
- имя - Словарь имён
- пример - Словарь примеров
- яп-ру (авто) - Японско-русская статья (правка, сгенерированная автоматически на основании некого источника)
Возможные статусы правок:
- не проверено
- отклонено
- принято
- принято автоматически
- восстановлено
Общие сведения
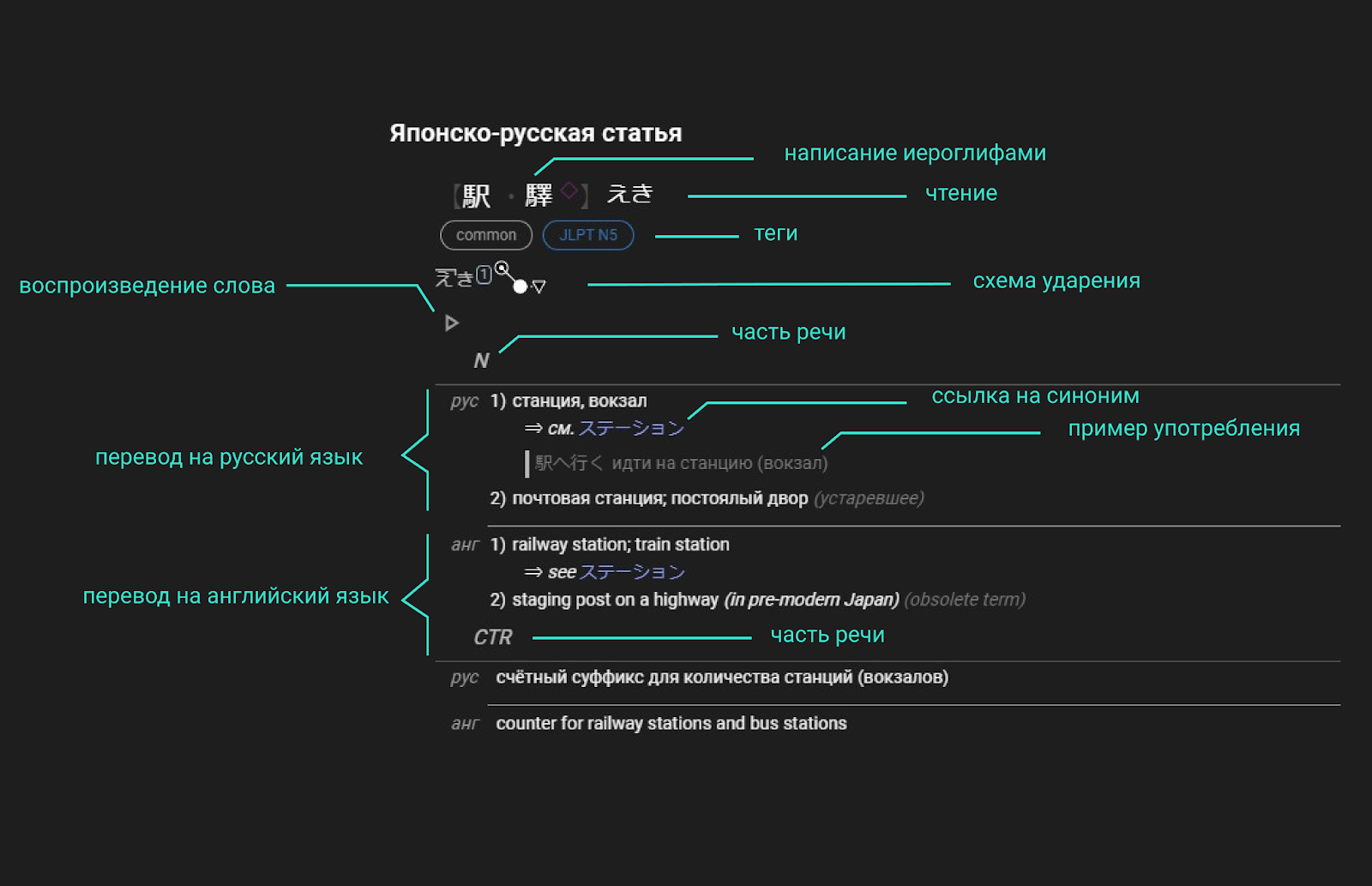
Структура статьи
Статьи в НЯРСе имеют древовидную структуру.
В заголовке каждая отдельная строка может содержать несколько чтений и несколько написаний. Для каждого чтения или написания есть свой набор тегов. Совокупность чтения и написания (иными словами, каждая отдельная строка в заголовке) в рамках статьи называется «словом».
Тело статьи состоит из блоков частей речи (для одного такого блока может быть указано несколько частей речи). Каждый такой блок включает в себя один-несколько языков, а уже в блоке языка указывается набор значений.
Можно представить эту структуру в виде диаграммы.

Соответствие слов статье
В большинстве словарей одной статье соответствует только одна связка написание+чтение, однако в НЯРСе несколько таких связок могут быть объединены в одну статью.
Например 【初七日】しょなぬか и 【初七日】しょなのか, по сути это просто разные прочтения одного и того же слова. Обычно в словарях такие слова делятся на несколько статей, при этом одна из них будет основной, а все остальные будут на неё ссылаться. Однако в НЯРСе такие слова будут объединены в одну статью, в этом случае написанием будет 初七日, а чтениями しょなぬか и しょなのか.
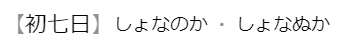
Подобные объединения возможны только в тех случаях, когда значения абсолютно идентичны для всех указанных написаний/чтений и есть общее чтение и/или написание. Кроме того, при объединении нужно стремиться к тому, чтобы оставалась только одна строка с чтением/написанием (про исключения см. гл. «Слова»).
Пример 1

Корректное объединение. Каждому написанию (слева) соответствует каждое из чтений (справа), таким образом в этом заголовке объединено 8 пар написание+чтение.
Пример 2

Некорректное объединение. Слова хоть и синонимичны, они не могут быть объединены по общему чтению и/или написанию.
Статус статьи
Статус статьи отображается иконкой в верхней части.
Неотредактированная статья -- статья не проверялась пользователями после добавления в словарь. Кроме того, такой статус должен быть у статей без русского перевода.
Статья не подтверждается источниками -- статус ставится, когда не удалось найти примеры употребления слова в реальных текстах, но при этом слово приводится каким-либо словарём.
Транскрипции
Для записи японских чтений в НЯРСе используется латиница, представленная немного модифицрованной системой Хэпбёрна.
Основное отличие заключается в том, что долгота обозначается двоеточием :
ドアアーム -> !doaa:mu
По этой причине おう может быть записано и как ou, и как o: в зависимости от употребления.
この上 -> このうえ -> konoue (お без удлинения, за ним идёт う)
おうぎゃく【横逆】 -> o:gyaku (お удлиняется при помощи う)
Конвертация между хираганой и катаканой происходит при помощи восклицательного знака !. Он работает как инвертор, то есть после этого символа азбука меняется на противоположную (за изначальную азбуку берётся хирагана). Например:
renga -> れんが (знака смены азбуки нет, значит конвертируется в хирагану)
!renga -> レンガ (знак смены азбуки стоит в начале, значит сразу же меняется азбука на катакану)
musui !kohaku !san -> むすいコハクさん (до
!будет хирагана, потом катакана, потом снова переключение на хирагану)
В случае транслитерации имён собственных, допустимо указывать их с прописной буквы:
【ウィーンの変位則】!Wi:n !no hen'isoku
закон смещения Вина
Редактирование
Самое главное при редактировании словаря — указать верный перевод, оформление вторично. Ничего страшного, если вы не укажете питч-акцент или какие-то теги -- главное, чтобы был верный перевод.
Частые ошибки при редактировании
Неверная расстановка скобок ( ) и [ ]
Пожалуйста, посмотрите главу «Использование скобок», там немного, но это сохранит уйму времени.
Ошибки при указании чтения латиницей
В НЯРСе для чтений используется модифицрованный Хэпбёрн, из-за это часто возникает недопонимание касательно записи おう, которое в Хэпбёрне записывается ou, но в НЯРСе записывается o: либо ou, в зависимости от того, это длинное o или комбинация гласных o+u.
Подробно про транскрипцию вы можете узнать в гл. «Транскрипции», а до тех пор вы можете использовать для записи азбуку хирагану/катакану, она будет автоматически сконвертирована в латиницу.
Первая статья
0. Вступление
В этом руководстве мы с вами создадим самую простую статью для слова 電化.
Для начала откроем редактор новой статьи, для этого нажимаем в левом меню кнопку "Добавить статью".

Нам откроется редактор, в котором некоторые поля уже заполнены по умолчанию:

Теперь пошагово укажем всю нужную информацию.
1. Написание и чтение
Нажмём на иконку карандаша около скобок 【】, нам откроется окно редактирования слова.
При помощи соответствущих кнопок мы можем добавить поля для написания и чтения, а затем указать их.
В нашем случае у слова 電化 написанием будет 電化, а чтением でんか.
Должно получиться следующее:
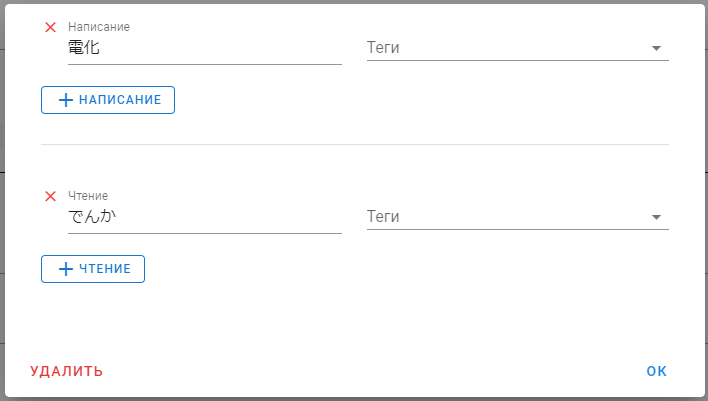
Теперь можно закрыть это окно, нажав «ОК» или кликнув вне границ окна.
2. Часть речи
Часть речи в японско-русском словаре выставляется по японскому слову.
По умолчанию при создании статьи выставляется часть речи UNC, что значит «неклассифицировано».
Нажмём на иконку карандаша около части речи (см. №2 на первом изображении в статье), нам откроется окно редактирования части речи.
Чтобы удалить часть речи, надо нажать на крестик справа от неё.
Давайте удалим существующие части речи и добавим «существительное»:
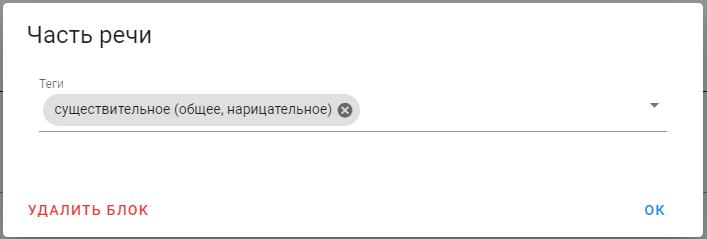
Теперь можно закрыть это окно, нажав «ОК» или кликнув вне границ окна.
3. Язык и значение
Добавим к части речи язык (на котором будет дано значение), для этого нажмём на кнопку +RUS.
Появится блок значений на русском языке, в котором по умолчанию уже есть одно значение.
Отредактируем его, нажав на иконку карандаша слева от значения.
В открывшемся окне текст значения указывается в самом первом поле, давайте укажем там значение «электрификация» и нажмём «ОК», чтобы закрыть окно редактирования.
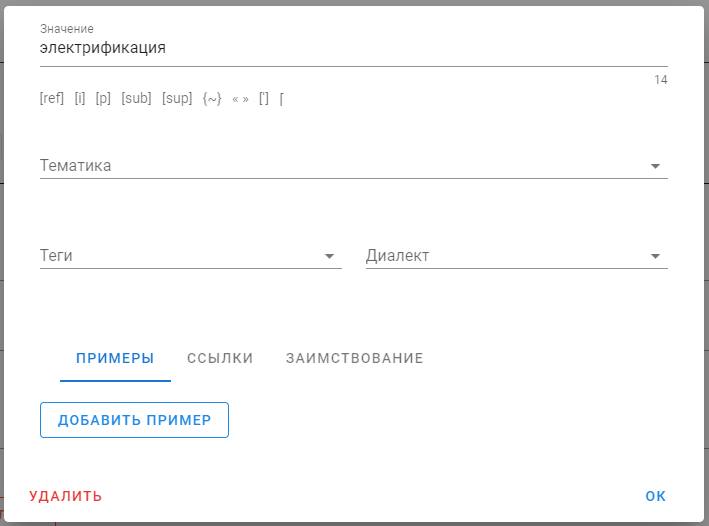
4. Сохранение
Таким образом у нас должна была получиться заполненная статья, как на скриншоте ниже:
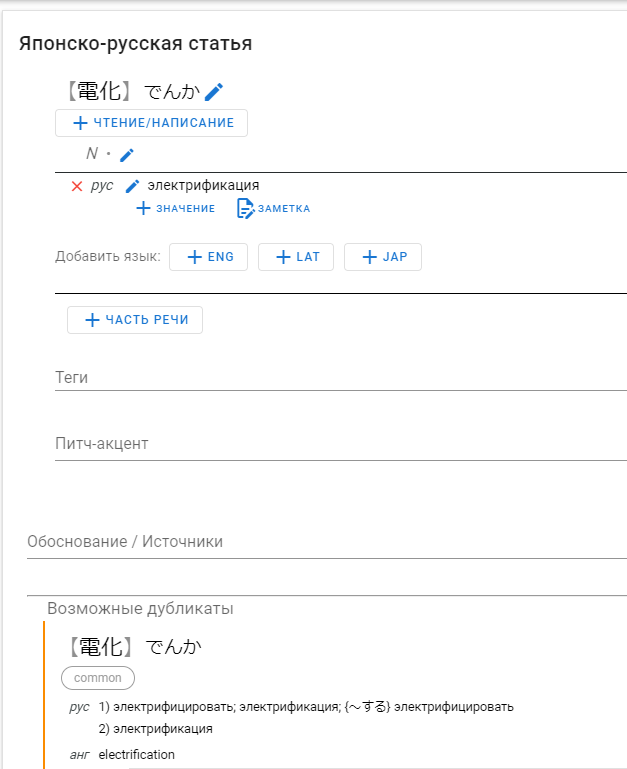
В принципе, остаётся только нажать кнопку «Сохранить» внизу слева, будет создана новая правка, после проверки которой будет создана новая статья.
В нашем случае, такая статья уже существует, о чём нам говорит блок «Возможные дубликаты», поэтому добавлять такую статью смысла нет, но пользуясь этим руководством, вы можете добавить любое другое слово, которого ещё нет в словаре.
5. Заключение
Как вы могли заметить, в интерфейсе есть куча функционала, который мы не затрагивали.
Он разбирается в последующих главах этого руководства, однако не стоит пытаться запомнить все нюансы разом.
Правки в любом случае проходят премодерацию, так что даже если вы с чем-то ошибётесь, модераторы это поправят.
Кроме того, не стесняйтесь спрашивать непонятные/спорные моменты, для этого у нас есть сообщество в Discord, где вам обязательно помогут и ответят на ваши вопросы: https://discord.gg/u7H5nsPWVB
Заголовок
Как мы уже разбирали ранее, заголовок состоит из «Слов» (каждая строка в заголовке соответствует отдельному «Слову»), каждое слово состоит из одного-нескольких чтений и написаний.
Чтение обязательно состоит только из хираганы/катаканы (в редакторе они пишутся латиницей), всё остальное же будет написанием.
Примеры написаний: 腰をくねらせる, 変更, α, α線維, LU分解, M2層, 2000
Примеры чтений: アースずきコンセント, コルンブいし
Из этого следует, что в статьях слов-гайрайго (и других, которые состоят из одной только каны) будет отсутствовать написание.
Чтение
Для записи чтения в НЯРСе используется латиница, представленная немного модифицрованной системой Хэпбёрна (см. «Транскрипции»).
Вы можете использовать для указания чтений кану, она будет автоматически сконвертирована в латиницу при сохранении правки, однако нужно иметь в виду, что возможны неоднозначные ситуации, в которых конвертация не сможет правильно отработать. Например, おう конвертируется в o:, но в некоторых ситуациях необходима запись ou (この上 -> このうえ -> kono:e, а должно быть konoue/kono ue).
Также при указании чтения рекомендуется разбивать его пробелами по границе слов (в том числе в составных словах). Пробелы можно использовать как при записи латиницей, так и при записи каной. Например: この上 -> この うえ, 腰をくねらせる -> koshi wo kuneraseru, 無担保転換社債 -> mutanpo tenkan shasai
Теги чтения
- (более) редкое чтение -- ミュンヒェン вместо более частого ミュンヘン
нестандартная запись каной -- テケツ вместо チケット- гикун (чтение по смыслу) или дзюкудзикун (особенное чтение) -- 煙草 たばこ
- ошибочное, неправильное чтение -- 月極 げっきょく
- старая орфография (кю-канадзукай) или архаичное чтение -- ゐ・ゑ・いふ в 言う・かは в 川・たけ вместо だけ・腕 かいな/かひな а не うで
Написание
Теги написания
- атэдзи (фонетическое использование кандзи) -- 滅茶苦茶・露西亜・烏克蘭・泥烏須
- дзюкудзикун (подобранный по смыслу кандзи с нестандартным чтением) -- 五月雨 майский дождь・部屋 часть дома
- неправильное, ошибочное написание -- 烏竜茶 -> 鳥竜茶
- нестандартная запись окуриганы -- 物語 -> 物語り
- нестандартная/редкая запись кандзи -- 布団 -> 蒲団, 切断 -> 截断
- устаревшее написание, кюдзитай формы -- 断截 -> 斷截
Устаревшее написание
Запись традиционными иероглифами необходимо указывать только в том случае, если обратная конвертация (из упрощённой формы в традиционную) неочевидна. Например:
嵐気 -> 嵐氣, в данном случае иероглифу 気 соответствует только 氣, значит написание 嵐氣 в статью включать не нужно.
弁慶 -> 辨慶, иероглифу 弁 соответствует несколько традиционных, значит традиционное написание нужно включить в статью.
На написания, содержащие традиционные иероглифы, необходимо повесить тег «устаревшее написание, кюдзитай формы».
Замена иероглифа на кану
Иногда встречаются слова, в которых один/несколько иероглифов заменены на их чтения.
Такие написания следует включать в статью, если они широко распространены.
Например: 濾過器 -> ろ過器
Слова
В рамках статьи «Словом» считается комбинация чтений + написаний, визуально слово соответствует одной строке в заголовке.
Как правило, в статье должно быть только одно слово (=строка с чтениями и написаниями), но в исключительных ситуациях в статью могут быть добавлены ещё слова, это делается при помощи кнопки «+чтение/написание».
Рассмотрим такую исключительную ситуацию на примере статьи «言葉巧み».

У этого слова есть несколько вариантов записи и чтений, но не все варианты записи слова читаются одинаково. Запись «言葉巧み・言葉たくみ・ことば巧み» может читаться как «ことばたくみ», а вот запись «言葉巧み・ことば巧み» имеет также чтение «ことばだくみ». Так как «言葉たくみ» не может читаться как «ことばだくみ», необходимо создать отдельное написание и чтение, нажав на кнопку «+чтение/написание». В таком случае чтения и значения будут находится не на одной строчке, а на двух разных.
Такое допустимо только при полной эквивалентности слов, в противном случае необходимо создать две отдельные статьи, как показано в примере ниже.

Питч-акцент
Питч-акцент указывается цифрами через запятую в поле справа от чтения (в окне редактирования чтения/написания).
Если питчей несколько, то их цифры следует указывать в порядке убывания. Например: 5,4,0.

Для указания питч-акцента крайне рекомендуется использовать соответствующие словари, в противном случае ваша правка может быть отклонена.
Назализация, редукция
Назализация и редукция указываются специальными обозначениями в тексте чтения.
Редуцированный слог выделяется скобками ( ), для указания назализации ставится символ ^ после выделяемого слога.
Возьмём для примера しちがつ, в данном случае нам нужно выделить редукцией し, а назализацией が. У нас получится следующая запись латиницей: (shi)chiga^tsu: 
Часть речи и язык
Языки
Всего в НЯРСе доступно 4 языка для указания значений: русский, английский, японский и латынь. При этом основными являются русский и английский.
Японский используется только как вспомогательный язык для статей, в которых нет русского/английского перевода. После добавления перевода на основные языки, японский следует удалить из статьи.
Латынь используется для указания номенклатурных названий биологических видов.
Части речи
Часть речи проставляется по японскому слову.
Значение
Значения следует писать со строчной (маленькой) буквы, за исключением имён собственных. Точка или точка с запятой в конце не ставится.
Перечисления
Чтобы указать несколько значений, используются разделительные символы: ;, и перенос строки.
Запятой разделяются синонимичные и очень близкие по значению переводы. Точкой с запятой разделяются более отдалённые по значению переводы. Перенос строки используется перед указанием производного слова (см. «Производные слова»).
С технической точки зрения, разделительные символы используются для связывания статьи с русскими/английскими значениями, по этой причине следует отключать разделение, когда оно не требуется -- например, в сложноподчинённых предложениях. Отключение производится при помощи слэша \.
студент\, обучающийся за границей
Использование скобок
В НЯРСе вы можете встретить ошибочное использование скобок, в том числе в отредактированных статьях.
Если вам такое встретится, пожалуйста, исправьте их в соответствии с нижеизложенными правилами.
Квадратные скобки []
Квадратные скобки используются для взаимозаменяемых слов
мобильный [передвижной] дом
->
мобильный дом, передвижной дом
Если скобки заменяют больше 1 слова, то для них указывается граница при помощи ⌈
пищевая [поваренная] соль
рассказ о ⌈своей жизни [своём собственном опыте]
башня ⌈с часами [для часов]
Круглые скобки ()
Круглые скобки обозначают факультативную часть определения:
(свой) родной город
->
свой родной город, родной город
Пояснения и различные уточнения заключаются в круглые скобки и в курсив:
Ямато [i](древнее название Японии)[/i]
Перечисления в скобках
Как и в обычном тексте значения, в скобках могут использоваться символы перечисления ;, и перенос строки.
грубо отёсанный [оструганный, околотый]
->
грубо отёсанный, грубо оструганный, грубо околотый
Отключить их действие можно при помощи экранирования слэшем \.
Обратите внимание, если круглые скобки выделены курсивом (текст примечания), то экранирование не нужно.
(блестящий с виду\, но жалкий по существу)
Перечисления в скобках должны быть грамматически согласованы с основным текстом, в противном случае надо раскрыть скобки и перечислить все значения отдельно:
НЕПРАВИЛЬНО: противовоспалительный препарат [средство]
ПРАВИЛЬНО: противовоспалительный препарат; противовоспалительное средство
Теги, тематики и диалекты
Тематики указываются для специализированных терминов. В своей текущей реализации это некая смесь между тематической категорией слова и пометой (в бумажном словаре).
Теги это своего рода стилистические пометы, уточняющие употребляемость слова. Например, тегами указывается, если слово относится к женской речи или является оскорбительным прозвищем.
Диалекты указываются для слов, взятых из различных диалектов японского языка.
Примеры, ссылки, заимствования
В окне редактирования значения внизу есть три вкладки: «Примеры», «Ссылки» и «Заимствования», рассмотрим их назначение.
Примеры
Примеры в составе статей используются исключительно для уточнения значения.
Примеры, которые здесь указываются, должны не просто показывать употребление слова, а давать какую-либо дополнительную информацию, например, показывать глагольное управление. Кроме того, крайне рекомендуется сокращать примеры до минимально возможных словосочетаний.
Рассмотрим следующие ситуации:
ふうとう【封筒】
封筒に封をする запечатывать конверт
Хороший пример. Показано употребление слова, в словосочетании отсутствуют лишние слова.
ふゆ【冬】
夏と冬どっちが好き? Что ты больше любишь: лето или зиму?
新しく冬のコート買わなくちゃ。 Мне надо купить новое зимнее пальто.
Плохие примеры. Не привносят никакой новой информации, являются распространёнными предложениями. Подобные примеры должны быть перенесены в словарь примеров.
Кроме того, в примерах могут приводиться составные слова, чтобы показать, как они образуются и какие возможны переводы.
れんぱつ【連発・連ぱつ】
6連発拳銃 шестизарядный револьвер
Фуригана в тексте примера
В японском тексте примера можно указывать фуригану, для этого используются следующий синтаксис: [кандзи|чтение], при этом чтения можно перечислять через |, в таком случае одно чтение справа будет соответствовать одному кандзи слева. Например:
[五月雨|さみだれ] -> 五月雨
[電話|でん|わ][番号|ばん|ごう] -> 電話番号
Фуригану стоит указывать только в спорных ситуациях.
Примечание: в статьях может встретиться 《 》: 七《なな》月《がつ》, это устаревшая разметка, её использование нежелательно.
Ссылки
Ссылки используются для указания отношений между статьями. Отношения могут быть следующих типов:
- синоним - слова полностью синонимичны
- частичный синоним - слова синонимичны не по всем значениям
- антоним
- сравни - прочие связи между словами
- сокращение от
Для синонимов и частичных синонимов ссылка проставляется с менее популярного слова на более популярное. Например, 濾過器 и フィルター, フィルター в данный момент более популярное слово, поэтому в статье 濾過器 нужно проставить ссылку на フィルター (обратная ссылка с フィルター на 濾過器 не нужна). Если выбрать более популярное слово не представляется возможным, допустимо проставить двухстороннюю ссылку, однако в целях удобства предпочтительнее всё же выбирать основное слово, на которое будут ссылаться все остальные синонимы.
Заимствования
В заимствовании указывается источник заимствования из другого языка. Например, チェックイン образовано от английского слова check-in.
Язык для заимствования указывается в соответствии с кодом ISO 639-3 за исключением васэй-эйго, для них используется код wasei.
ББ-коды
В НЯРСе используются рамочные ББ-коды, т.е. они обрамляют собой текст, который обрабатывают.
При нажатии на кнопку тега на месте, где находится курсор, вставятся открывающий и закрывающий теги, между которыми пишется необходимый текст.
Также можно сначала выделить нужный текст, а затем нажать на кнопку тега, чтобы автоматически выделить выбранный текст тегом.
[i]
Тег [i] используется для выделения курсивом примечаний и пояснений.
См. главу «Круглые скобки»
[p]
Тегом [p] выделяются общепринятые сокращения в тексте. В будущем планируется реализовать всплывающую подсказку для сокращений, выделенных таким образом.
VIII-VI [p]вв.[/p] до [p]н.э.[/p] на территории [p]совр.[/p] уезда Фэнъян
{~} (Производные слова)
{~ } используется для указания перевода производных слов.
Производные слова должны указываться латиницей (см. «Транскрипции») в начале строки.
проезд без билета
{~suru} ехать зайцем; ехать без билета
Производные слова не нужно указывать, если они очевидны из частей речи для этой статьи и также очевиден их перевод.
В данном случае указание производных слов избыточно:
いちじゅん【一巡】
(существительное (общее, нарицательное), noun or participle which takes the aux. verb suru)
обход, патрулирование
{~suru} обходить, патрулировать
Также есть рамочная вариация этого тега: {... ~ }
ぎせい【犠牲】
жертва
{...wo~ni shite} ценой [i]чего-л.[/i]
«»
Кавычки «ёлочки», используемые в русском языке. Следует использовать их вместо "".
[']
Ставит ударение, например [']о[/'] = о́
[sub] [sup]
[sub] ー нижний индекс
[sup] ー верхний индекс
оба используются для математики, химии и т.д.
CH[sub]2[/sub]=CHCl -> CH2=CHCl
10[sup]5[/sup] -> 105
[ref]
Больше не используется.
[ref] предназначен для указания ссылки на другую статью. Создаёт гиперссылку, при переходе по которой открывается страница поиска по выбранному слову.
Если указать идентификатор статьи, то перенаправит пользователя сразу на страницу этой статьи.
[ref]僕[/ref] — при нажатии на 僕 откроется страница с поиском по этому слову со всеми статьями.
[ref=CX7D]僕[/ref] — сразу же откроется нужная статья
Идентификатор берётся из ссылки на статью, например: https://nyars.org/jp/CX7D, в данном случае CX7D это идентификатор.